
2022-11-16
992

Fatcache学习笔记
分类专栏:
摘录笔记
文章标签:
学习笔记
数据存储
原创
前言
秋招差不多结束了,基本确定了之后去的公司,没了笔试面试和实习,最近也就闲了下来。
打算和朋友一起做点开源项目,暂定方向就是数据存储这块。于是这两周也是在学数据存储相关的知识,比如SSD、底层文件系统、lsm-tree等等。
我一直以来都有将我学过的东西记录下来的习惯,不过最近都是以知识脑图的形式记录在wps里。考虑到我已经很久没有发布过技术博文了,我还是打算将我最近学的整理一下,以笔记的形式记录在博客当中,方便日后回顾,同时也是分享出来一起学习。
NOTE:该文很多内容都摘自git-hulk。我也是通过他整理的资料去学习fatcache,侵删。
简介
fatcache是来自Twitter, 基于SSD上面实现的cache, 使用mc的协议,数据存储在SSD (Ps:memcached是将数据放在内存中)。 fatcache的数据放在SSD(其实机械盘也可以,只是性能不佳), 所以相对于内存cache, 如memcached、redis,能容纳更多数据。
主要特性:
- 通过slab管理数据,跟memcached类似,但稍有不同
- 通过索引查找数据
- 单线程
- 针对写SSD做了优化
一、slab分配机制
1.背景知识
SSD特性
SSD由于硬件的特性,改写前需要擦除(erase),擦除的单位一般是128个page(512KB),每个擦除单元称为块(block)。也就是说即时改写的数据只有几个比特,也必须重写整个block,造成了写的浪费,而这种现象也就是我们平时所说的写放大。
内存和硬盘读写速度
内存读写速度快,容量小,价格贵。 硬盘读写速度慢,容量大,价格较内存便宜。
其中要注意的是,两者读写速度是数量级的存在。所以很多时候在设计程序时,往往就是将一些热数据放在内存中来加快读写。
2.slab
因为之前讲SSD读写特性问题,同时也是为了方便内存和磁盘空间的管理,fatcache将内存和磁盘分为一块块的slab。每当需要空间来存储键值对时,fatcache都会找到一个能满足其空间需求的slab,将其中的一个item分配给它。
3.slab class
由于并不是所有的kv的长度都是一样的,这就需要不同item长度的slab, 而slabclass就是这些 不同长度item的slab的集合。在一般设计slabclass的时候,可以把slabclass看作一个item长度递增 的数组,并把slab放到对应的队列中。当在添加数据的时候,找到能容纳kv长度的slabclass,然后从未使用完或者空闲的slab, 分配一个item空间。
如slabclass有n级, 假设每个slab是1M, 第一级item长度是100byte, 每级增长因子是1.2。
第一级item的长是100bytes, item count = 1M/100
第二级item的长度是100byte*1.2 = 120byte, item count = 1M/120
第三级item的长度是120*1.2 = 144bytes, item count = 1M/144
以此类推.
当需要申请80byte的内存时候, 从第一级开始找,直到遇到第一个比它大的slab, 这里就是第一级的slab。 如果要申请130bytes的内存, 就是找到第三级。
PS:可以理解为slab根据大小分成了不同类型,而这个类型就是slab class
4.memory and disk slab
fatcache的slab来自两个地方,一个是内存,另一个是磁盘。在启动的时候,可以指定内存slab大小, 默认是64M, 我们也会指定磁盘分区。然后再把内存和磁盘的空间,切分为一块块slab, 再添加到free slab队列。 fatcache的内存slab, 充当的角色是写缓存,每次写的时候,一定是写在内存slab, 当写入时,发现没有内存slab, 就将最老的slab刷入磁盘。
5.slab在fatcache的使用
看过上面的内容之后,应该能知道slab大概的样子,以及Slabclass是干嘛的。 slabcloass每一级slab可以分配 的item长度和数量是固定的, 所以slab可能会有三种状态:
- free slab(完全没有使用)
- partial slab(部分使用),
- full slab(全部使用).
最开始, 由于没开始使用,只会有free slab, 当使用一段时间后,就转换为partial slab, 如果这个slab已经被分配完, 则会变为full slab.
在fatcache中, 会维护这三种状态的slab, 其中free slab, full slab队列是slabclass所有级公用,partial slab是每一级都有一个 队列。
当某一级需要分配空间, 会经历下面的步骤:
- 如果还有内存slab未写满,直接分配地址,返回。
- 如果所有内存slab已经写满, 从内存full slab队列头部,剔除一个slab, 交换到磁盘slab,空出内存slab, 重新分配
6.slab空洞问题
fatcache分配时每次都是从Slab末端开始分配。也就是说,如果item删除, 我们并不会重新利用,相当于这个item只有在内存slab耗尽时,刷到磁盘slab才会重新利用,这样这个带有空洞的slab 被刷到磁盘,也就是磁盘的数据也会有空洞, 不仅仅是内存刷到磁盘的slab造成空洞,直接删除磁盘slab里的item,也会有空洞,造成空洞的过程类似下面:
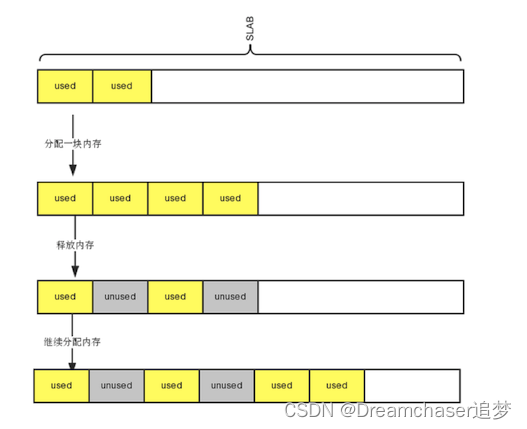 对于内存空洞,解决方案可以,对每个slab增加一个队列,记录空洞地址,使用时,优先从空洞队列分配,无空洞时, 从slab后面分配。同时放回slab时,如果是最后一个分配,直接放回slab, 否则放到空洞队列。
对于内存空洞,解决方案可以,对每个slab增加一个队列,记录空洞地址,使用时,优先从空洞队列分配,无空洞时, 从slab后面分配。同时放回slab时,如果是最后一个分配,直接放回slab, 否则放到空洞队列。
NOTE: 上面说的是针对内存空洞,不包含磁盘slab,因为fatcache主要是使用磁盘slab, 如果对每个磁盘slab, 增加空洞队列,可能会耗掉不少内存,需要提前评估。
注:这个应该并不是个“问题”,而是个trade-off的design。如果跟原作者所说的去额外维护一个free-slot-lits来track这些位置,即放弃了原设计的append的策略,带来的问题就是新和旧的数据被写入到同一个slab中,这样的混合的slab如果在生命周期特征比较明显的负载上,原始的FIFO的效果肯定就差很多了。尤其是在用大容量的SSD做backend的背景下,space cost应该是个弱考虑因素。 (grayxu on 2021/11/3)
二、索引机制
1.为什么要有索引机制?
fatcache的数据大部分在磁盘,只有小部分在内存中。查找一个key, 如果没有索引,每次都要到磁盘做查找,效率很低, 而且会有多次磁盘读。有了索引之后,在索引记录key, 以及数据所在的位置。查找时,只需判断索引是否存在,如果存在, 直接根据记录的磁盘位置,读取数据,最多只有一次读IO, 如果内存中找不到索引,说明key不存在,直接返回空。
2.索引数据结构
我们可以先来看一下索引(itemx)的定义,在fc_itemx.h里面
struct itemx {
// 队列指针
STAILQ_ENTRY(itemx) tqe; /* link in index / free q */
// key的sha1加密值,如果sha1一样,认为是同一个key.
uint8_t md[20]; /* sha1 message digest */
// 这个key对应value的slab id.
uint32_t sid; /* owner slab id */
// 这个ke对应value在slab里面的偏移位置
uint32_t offset; /* item offset from owner slab base */
// 我们协议看到的cas unique值。
uint64_t cas; /* cas */
} __attribute__ ((__packed__));
存放索引的数据结构类似于Java中的HashMap,原理是hash+链表。
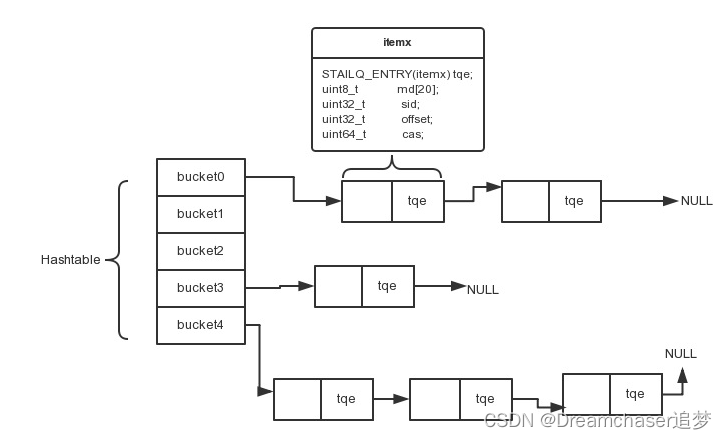
fatcache在启动的时候,会根据设定索引的最大空间,然后把索引全部初始化放到索引的空闲列表。
-
当set一个key-value的时候,fatcache会从索引的空闲队列中,拿出一个索引,然后记录key的sha1加密值以及数据存放的位置。
-
当get一个key的时候, 先把key转为sha1值,然后从索引表里面找到索引项,然后读到数据。
-
当删除一个数据,只需要把索引直接干掉。不需要真正的删除数据,下次过来就不知道索引,也会找不到数据,空出的空间会重新利用
3.数据的查找过程
- 由key找到索引itemx且没有过期
- 根据索引中sid找到slab info,根据slab info中mem字段判断item是在内存中还是磁盘中
- 然后根据sid所在slab class id,计算item长度, 从内存或者disk读取到数据,返回
PS:索引数量是用户可配置的,如果索引耗完,就会通过slab_evict来把老的slab剔除,回收索引
总结
fatcache是一款很不错的针对SSD开发的存储软件,其特点如下:
- 单线程, 实现更加简单,但性能没多线程的好
- 无随机写,通过slab管理,转化为顺序写,减少小块IO写,无写放大
- 随机读, 读性能没有写性能好
- 索引管理, 快速判断数据是否存在,同时可以快速定位数据的位置,最多只有一次IO
- slab分为内存和磁盘两种, 读写磁盘是direct io,不会使用pagecache, 内存slab更多是写缓冲的角色
fatcache很适合用在那些对于数据响应时间并不是要求太高,最好是介于全内存和DB之间,同时数据量比较大的场景。
对我而言,fatcache的slab分配机制和索引机制是非常有借鉴意义的。


评论