
2022-11-16
510

Leveldb学习笔记:leveldb的使用与原理探究
分类专栏:
摘录笔记
文章标签:
摘录笔记
原创
前言
秋招差不多结束了,基本确定了之后去的公司,没了笔试面试和实习,最近也就闲了下来。
打算和朋友一起做点开源项目,暂定方向就是数据存储这块。于是这两周也是在学数据存储相关的知识,比如SSD、底层文件系统、lsm-tree等等。
我一直以来都有将我学过的东西记录下来的习惯,不过最近都是以知识脑图的形式记录在wps里。考虑到我已经很久没有发布过技术博文了,我还是打算将我最近学的整理一下,以笔记的形式记录在博客当中,方便日后回顾,同时也是分享出来一起学习。
一、leveldb是什么?
LevelDB is a fast key-value storage library written at Google that provides an ordered mapping from string keys to string values.
Leveldb是一个持久化存储的KV系统。 实际上,它就是我们平时说的底层存储引擎,或者说是一个数据库,我们平时所熟知的redis底层用到存储引擎rocketdb就是从leveldb上演化过来的。
二、leveldb的使用
这里分享一个看源码的心得,当你拿到一个陌生项目的源码时,多看看它是如何使用的,从使用入手,以此为切入点去阅读关键代码,这样会轻松很多。
ps:在leveldb项目doc目录下有个介绍其使用的文档index.md,以下多是摘自它的翻译。
1.打开一个数据库
leveldb 数据库都有一个名字,该名字对应文件系统上的一个目录,该数据库内容全都存在该目录下。下面的例子显示了如何打开一个数据库,必要时创建数据库:
#include <cassert>
#include "leveldb/db.h"
leveldb::DB* db;
leveldb::Options options;
options.create_if_missing = true;
leveldb::Status status = leveldb::DB::Open(options, "/tmp/testdb", &db);
assert(status.ok());
...
如果你想在数据库已存在的时候触发一个异常,将下面这行配置加到 leveldb::DB::Open 调用之前:
options.error_if_exists = true;
2.Status
你也许注意到上面的 leveldb::Status 返回类型,leveldb 中大部分方法在遇到错误的时候会返回该类型的值,你可以检查它是否 ok,然后打印相关的错误信息:
leveldb::Status s = ...;
if (!s.ok()) cerr << s.ToString() << endl;
3.关闭一个数据库
当数据库不再使用的时候,像下面这样直接删除数据库对象就可以了:
... open the db as described above ...
... do something with db ...
delete db;
4.数据库读写
leveldb提供Put,Delete和Get方法去修改/查询数据库,下面的代码展示了将 key1 对应的 value 移动到 key2 下。
std::string value;
leveldb::Status s = db->Get(leveldb::ReadOptions(), key1, &value);
if (s.ok()) s = db->Put(leveldb::WriteOptions(), key2, value);
if (s.ok()) s = db->Delete(leveldb::WriteOptions(), key1);
5.原子更新
需要注意的是,在上一小节中如果进程在 Put key2 后 Delete key1 之前挂了,那么同样的 value 将被存储在多个 key 下。可以通过使用 WriteBatch 原子地应用一组操作来避免类似的问题。
#include "leveldb/write_batch.h"
...
std::string value;
leveldb::Status s = db->Get(leveldb::ReadOptions(), key1, &value);
if (s.ok()) {
leveldb::WriteBatch batch;
batch.Delete(key1);
batch.Put(key2, value);
s = db->Write(leveldb::WriteOptions(), &batch);
}
WriteBatch 保存着一系列将被应用到数据库的操作,这些操作会按照添加的顺序依次被执行。注意,我们先执行 Delete 后执行 Put,这样如果 key1 和 key2 一样的情况下我们也不会错误地丢失数据。
除了原子性,WriteBatch 也能加速更新过程,因为可以把一大批独立的操作添加到同一个 batch 中然后一次性执行。
6.同步写
默认情况下,leveldb 每个写操作都是异步的:进程把要写的内容丢给操作系统后立即返回,从操作系统内存到底层持久化存储的传输是异步进行的。
可以为某个特定的写操作打开同步标识:write_options.sync = true,以等到数据真正被记录到持久化存储后再返回(在 Posix 系统上,这是通过在写操作返回前调用 fsync(...) 或 fdatasync(...) 或 msync(..., MS_SYNC) 来实现的)。
leveldb::WriteOptions write_options;
write_options.sync = true;
db->Put(write_options, ...);
异步写通常比同步写快 1000 倍。异步写的缺点是,一旦机器崩溃可能会导致最后几个更新操作丢失。注意,仅仅是写进程崩溃(而非机器重启)不会造成任何损失,因为哪怕 sync 标识为 false,在进程退出之前,写操作也已经从进程内存推到了操作系统。
异步写通常可以安全使用。比如你要将大量的数据写入数据库,如果丢失了最后几个更新操作,也可以重做整个写过程。如果数据量非常大,一个优化点是采用混合方案,每进行 N 个异步写操作则进行一次同步写,如果期间发生了崩溃,重启从上一个成功的同步写操作开始即可。(同步写操作可以同时更新一个标识,描述崩溃时重启的位置)
WriteBatch 可以作为异步写操作的替代品,多个更新操作可以放到同一个 WriteBatch 中然后通过一次同步写(即 write_options.sync = true)一起落盘。
7.并发
一个数据库同时只能被一个进程打开。leveldb 会从操作系统获取一把锁来防止多进程同时打开同一个数据库。在单个进程中,同一个 leveldb::DB 对象可以被多个并发线程安全地使用,也就是说,不同的线程可以在不需要任何外部同步原语的情况下,写入、获取迭代器或者调用 Get(leveldb 实现会确保所需的同步)。但是其它对象,比如 Iterator 或者 WriteBatch 需要外部自己提供同步保证,如果两个线程共享此类对象,需要使用自己的锁进行互斥访问。具体见对应的头文件。
8.迭代器
下面的用例展示了如何打印数据库中全部的 (key, value) 对。
leveldb::Iterator* it = db->NewIterator(leveldb::ReadOptions());
for (it->SeekToFirst(); it->Valid(); it->Next()) {
cout << it->key().ToString() << ": " << it->value().ToString() << endl;
}
assert(it->status().ok()); // Check for any errors found during the scan
delete it;
下面的用例展示了如何打印 [start, limit) 范围内的数据:
for (it->Seek(start);
it->Valid() && it->key().ToString() < limit;
it->Next()) {
...
}
当然你也可以反向遍历(注意,反向遍历可能要比正向遍历慢一些,具体见前面的读性能基准测试):
for (it->SeekToLast(); it->Valid(); it->Prev()) {
...
}
9.Snapshots快照
快照提供了针对整个 KV 存储的一致性只读视图(consistent read-only views)。ReadOptions::snapshot 不为 null 表示读操作应该作用在 DB 的某个特定版本上;若为 null,则读操作将会作用在当前版本的一个隐式的快照上。
快照通过调用 DB::GetSnapshot() 方法创建:
leveldb::ReadOptions options;
options.snapshot = db->GetSnapshot();
... apply some updates to db ...
leveldb::Iterator* iter = db->NewIterator(options);
... read using iter to view the state when the snapshot was created ...
delete iter;
db->ReleaseSnapshot(options.snapshot);
注意,当一个快照不再使用的时候,应该通过 DB::ReleaseSnapshot 接口进行释放。
10.Slice
it->key() 和 it->value() 调用返回的值是 leveldb::Slice 类型(和go语言中slice切片类似)。Slice 是一个简单的数据结构,包含一个长度和一个指向外部字节数组的指针,返回一个 Slice 比返回一个 std::string 更高效,因为不需要隐式地拷贝大量的 keys 和 values。另外,leveldb 方法不返回 \0 截止符结尾的 C 风格字符串,因为 leveldb 的 keys 和 values 允许包含\0字节。
C++ 风格的 string 和 C 风格的空字符结尾的字符串很容易转换为一个 Slice:
leveldb::Slice s1 = "hello";
std::string str("world");
leveldb::Slice s2 = str;
一个 Slice 也很容易转换回 C++ 风格的字符串:
std::string str = s1.ToString();
assert(str == std::string("hello"));
在使用 Slice 时要小心,要由调用者来确保 Slice 指向的外部字节数组有效。例如,下面的代码就有 bug :
leveldb::Slice slice;
if (...) {
std::string str = ...;
slice = str;
}
Use(slice);
当 if 语句结束的时候,str 将会被销毁,Slice 的指向也随之消失,后面再用就会出问题。
11.比较器(Comparator)
前面的例子中用的都是默认的比较函数,即逐字节按字典序比较。你可以自定义比较函数,然后在打开数据库的时候传入,只需要继承 leveldb::Comparator 然后定义相关逻辑即可,下面是一个例子:
class TwoPartComparator : public leveldb::Comparator {
public:
// Three-way comparison function:
// if a < b: negative result
// if a > b: positive result
// else: zero result
int Compare(const leveldb::Slice& a, const leveldb::Slice& b) const {
int a1, a2, b1, b2;
ParseKey(a, &a1, &a2);
ParseKey(b, &b1, &b2);
if (a1 < b1) return -1;
if (a1 > b1) return +1;
if (a2 < b2) return -1;
if (a2 > b2) return +1;
return 0;
}
// Ignore the following methods for now:
const char* Name() const { return "TwoPartComparator"; }
void FindShortestSeparator(std::string*, const leveldb::Slice&) const {}
void FindShortSuccessor(std::string*) const {}
};
现在使用这个自定义比较器创建一个数据库:
TwoPartComparator cmp;
leveldb::DB* db;
leveldb::Options options;
options.create_if_missing = true;
options.comparator = &cmp;
leveldb::Status status = leveldb::DB::Open(options, "/tmp/testdb", &db);
...
12.向后兼容性
比较器 Name() 方法返回的结果在创建数据库时会被绑定到数据库上,后续每次打开都会进行检查,如果名称改了,对 leveldb::DB::Open 的调用就会失败。因此,当且仅当在新的 key 格式和比较函数与已有的数据库不兼容而且已有数据不再被需要的时候再修改比较器名称。总而言之,一个数据库只能对应一个比较器,而且比较器由名字唯一确定,一旦修改名称或比较器逻辑,数据库的操作逻辑统统会出错,毕竟 leveldb 是一个有序的 KV 存储。
如果非要修改比较逻辑呢?你可以根据预先规划一点一点的演进你的 key 格式,注意,事先的演进规划非常重要。比如,你可以在每个 key 的结尾存储一个版本号(大多数场景,一个字节足矣),当你想要切换到新的 key 格式的时候(比如上面的例子 TwoPartComparator处理的 keys 中),那么需要做的是:
- 保持相同的比较器名称
- 递增新 keys 的版本号
- 修改比较器函数以让其使用版本号来决定如何进行排序
13.性能调优
通过修改 include/leveldb/options.h 中定义的类型的默认值来对 leveldb 的性能进行调优。
Block 大小
leveldb 把相邻的 keys 组织在同一个 block 中,block 是数据在内存和持久化存储传输之间的基本单位。默认的未压缩 block 大小大约为 4KB,经常批量扫描大量数据的应用可能希望把这个值调大,而针对数据只做“点读”的应用则可能希望这个值小一些。但是,没有证据表明该值小于 1KB 或者大于几个 MB 的时候性能会表现得更好。另外要注意的是,使用较大的 block size,压缩效率会更高效
压缩
每个 block 在写入持久化存储之前都会被单独压缩。压缩默认是开启的,因为默认的压缩算法非常快,而且对于不可压缩的数据会自动关闭压缩功能,极少有场景会让用户想要完全关闭压缩功能,除非基准测试显示关闭压缩会显著改善性能。按照下面方式即可关闭压缩功能:
leveldb::Options options;
options.compression = leveldb::kNoCompression;
... leveldb::DB::Open(options, name, ...) ....
缓存
数据库的内容存储在文件系统中的一组文件中,每个文件都存储了一系列压缩后的 blocks,如果 options.block_cache 是非 NULL,则用于缓存经常使用的已解压缩 block 内容。
#include "leveldb/cache.h"
leveldb::Options options;
options.block_cache = leveldb::NewLRUCache(100 * 1048576); // 100MB cache
leveldb::DB* db;
leveldb::DB::Open(options, name, &db);
... use the db ...
delete db
delete options.block_cache;
注意 cache 保存的是未压缩的数据,因此应该根据应用程序所需的数据大小来设置它的大小。(已压缩数据的缓存工作交给操作系统的 buffer cache 或者用户自定义的 Env 实现去干。)
当执行一个大块数据读操作时,应用程序可能想要取消缓存功能,这样读进来的大块数据就不会导致当前 cache 中的大部分数据被置换出去,我们可以为它提供一个单独的 iterator 来达到该目的:
leveldb::ReadOptions options;
options.fill_cache = false;
leveldb::Iterator* it = db->NewIterator(options);
for (it->SeekToFirst(); it->Valid(); it->Next()) {
...
}
Key 的布局
注意,磁盘传输和缓存的单位都是一个 block,相邻的 keys(已排序)总在同一个 block 中,因此应用可以通过把需要一起访问的 keys 放在一起,同时把不经常使用的 keys 放到一个独立的键空间区域来提升性能。
举个例子,假设我们正基于 leveldb 实现一个简单的文件系统。我们打算存储到这个文件系统的数据类型如下:
filename -> permission-bits, length, list of file_block_ids
file_block_id -> data
我们可以给上面表示 filename 的 key 增加一个字符前缀,例如 '/',然后给表示 file_block_id 的 key 增加另一个不同的前缀,例如 '0',这样这些不同用途的 key 就具有了各自独立的键空间区域,扫描元数据的时候我们就不用读取和缓存大块文件内容数据了。
过滤器
鉴于 leveldb 数据在磁盘上的组织形式,一次 Get() 调用可能涉及多次磁盘读操作,可配置的 FilterPolicy 机制可以用来大幅减少磁盘读次数。
leveldb::Options options;
// 设置启用基于布隆过滤器的过滤策略
options.filter_policy = NewBloomFilterPolicy(10);
leveldb::DB* db;
// 用该设置打开数据库
leveldb::DB::Open(options, "/tmp/testdb", &db);
... use the database ...
delete db;
delete options.filter_policy;
上述代码将一个基于布隆过滤器的过滤策略与数据库进行了关联,基于布隆过滤器的过滤方式依赖于如下事实,在内存中保存每个 key 的部分位(在上面例子中是 10 位,因为我们传给 NewBloomFilterPolicy 的参数是 10),这个过滤器将会使得 Get() 调用中非必须的磁盘读操作大约减少 100 倍,每个 key 用于过滤器的位数增加将会进一步减少读磁盘次数,当然也会占用更多内存空间。我们推荐数据集无法全部放入内存同时又存在大量随机读的应用设置一个过滤器策略。
如果你在使用自定义的比较器,应该确保你在用的过滤器策略与你的比较器兼容。举个例子,如果一个比较器在比较 key 的时候忽略结尾的空格,那么 NewBloomFilterPolicy 一定不能与此比较器共存。相反,应用应该提供一个自定义的过滤器策略,而且它也应该忽略 key 的尾部空格,示例如下:
class CustomFilterPolicy : public leveldb::FilterPolicy {
private:
FilterPolicy* builtin_policy_;
public:
CustomFilterPolicy() : builtin_policy_(NewBloomFilterPolicy(10)) {}
~CustomFilterPolicy() { delete builtin_policy_; }
const char* Name() const { return "IgnoreTrailingSpacesFilter"; }
void CreateFilter(const Slice* keys, int n, std::string* dst) const {
// Use builtin bloom filter code after removing trailing spaces
std::vector<Slice> trimmed(n);
for (int i = 0; i < n; i++) {
trimmed[i] = RemoveTrailingSpaces(keys[i]);
}
return builtin_policy_->CreateFilter(&trimmed[i], n, dst);
}
};
当然也可以自己提供非基于布隆过滤器的过滤器策略,具体见 leveldb/filter_policy.h。
14.校验和(Checksums)
leveldb 将校验和与它存储在文件系统中的所有数据进行关联,对于这些校验和,有两个独立的控制:
ReadOptions::verify_checksums 可以设置为 true,以强制对所有从文件系统读取的数据进行校验。默认为 false,即,不会进行这样的校验。
Options::paranoid_checks 在数据库打开之前设置为 true ,以使得数据库一旦检测到数据损毁立即报错。根据数据库损坏的部位,报错可能是在打开数据库后,也可能是在后续执行某个操作的时候。该配置默认是关闭状态,即,持久化存储部分损坏数据库也能继续使用。
如果数据库损坏了(当开启 Options::paranoid_checks 的时候可能就打不开了),leveldb::RepairDB() 函数可以用于对尽可能多的数据进行修复。
15.近似空间大小
GetApproximateSizes 方法用于获取一个或多个键区间占据的文件系统近似大小(单位, 字节)
leveldb::Range ranges[2];
ranges[0] = leveldb::Range("a", "c");
ranges[1] = leveldb::Range("x", "z");
uint64_t sizes[2];
db->GetApproximateSizes(ranges, 2, sizes);
上述代码结果是,size[0] 保存 [a..c) 区间对应的文件系统大致字节数。size[1] 保存 [x..z) 键区间对应的文件系统大致字节数。
16.环境变量
由 leveldb 发起的全部文件操作以及其它的操作系统调用最后都会被路由给一个 leveldb::Env 对象。用户也可以提供自己的 Env 实现以达到更好的控制。比如,如果应用程序想要针对 leveldb 的文件 IO 引入一个人工延迟以限制 leveldb 对同一个系统中其它应用的影响:
// 定制自己的 Env
class SlowEnv : public leveldb::Env {
... implementation of the Env interface ...
};
SlowEnv env;
leveldb::Options options;
// 用定制的 Env 打开数据库
options.env = &env;
Status s = leveldb::DB::Open(options, ...);
17.可移植
如果某个特定平台提供 leveldb/port/port.h 导出的类型/方法/函数实现,那么 leveldb 可以被移植到该平台上,更多细节见 leveldb/port/port_example.h。
另外,新平台可能还需要一个新的默认的 leveldb::Env 实现。具体可参考 leveldb/util/env_posix.h 实现。
三、原理探究
1.始于lsm-tree
leveldb设计思路始于lsm-tree的存储策略。 lsm-tree本质上一种存储策略,是一种优化写性能的一种方法。
它将我们平常对于kv键值对的增删改查操作由随机写改为顺序写,由此来提升写入的性能。
lsm-tree 的核心思路就是在内存中维护一个有序的数据结构(可以是跳表、排序树等等)。当一个写操作进来时,我们对内存中的数据结构进行修改即可。为了避免此次修改在遇到特殊情况(如宕机、进程崩溃)造成的数据丢失问题,此时会将修改转化为一条日志,将其顺序写入日志文件中,避免数据丢失。
当内存中的数据结构大小超过一定阈值,再将内存中的数据结构持久化到硬盘中,此时的写入也是顺序写。性能自然就上来了。
但这也不是没有缺点,其缺点在于当我查询的时候,如果该键值不在内存中,那么我就要去硬盘中查找。而此时针对我们查找的内容它是分了几个不同的小文件的,所以在极端情况下可能要读取多次,从而找到对应key-value对。
2.架构设计与核心设计思路
2.1 架构设计
leveldb的架构设计如下:
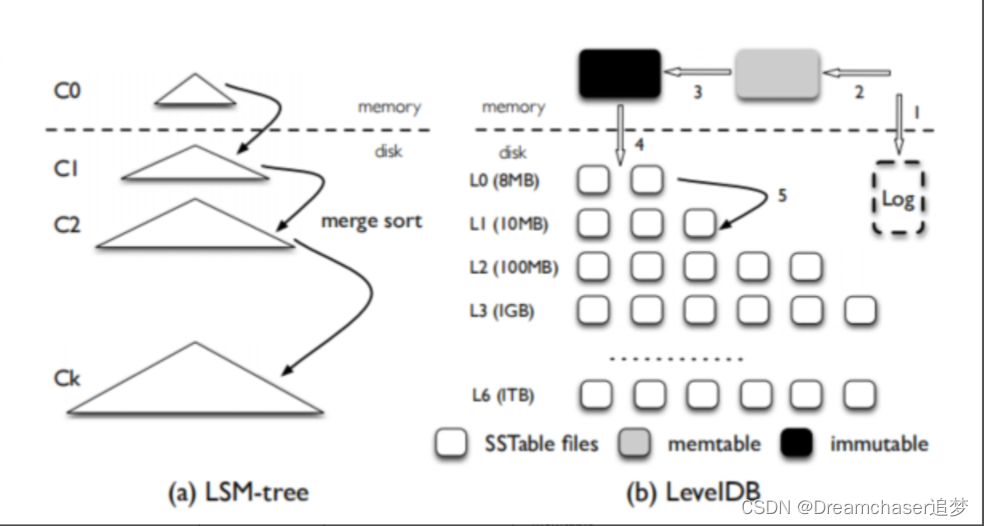 上图中有几个角色:
上图中有几个角色:
- Log:磁盘日志文件
- memtable、immutable:在内存中有序跳表,memtable可写,immutable表示已经关闭的数据结构,只读,等待持久化到磁盘
- SSTable files:排序的字符串表(SSTable)文件,分为七个level
核心思路就是利用lsm-tree的存储
2.2 读写过程
接下来我们先通过读写过程中操作来简单解释一下上述的架构图。
数据写入过程
- 将此次插入转换成一条日志插入日志文件中
- 将此次插入的数据应用到内存中memtable中
通常情况下,上述两个操作就完成了一次数据写入,相较于传统意义上的随机写,该方式只用了一次顺序写和内存写入,性能自然能快上不少。
数据删除过程
数据删除并非真正去磁盘上擦除数据,而是采取标记的方式。
- 当数据还在内存中没有持久化到磁盘时,此时只需在内存中删除对应的数据结构即可
- 当数据已经持久化到磁盘中时,此时我将打上一个Key的删除标记,表示已经删除,至于真正删除要等到后面执行压缩操作
数据修改过程
这里的修改可以理解为先删后插入,老的value会失效,但并非真正删除。
数据查询过程
- 查找内存中memtable和Immutable
- 如果内存中找不到,那么就需要查找磁盘,此时会以一种级联的方式去从C0开始搜索组件,直到在最小的组件Ci中找到所需的数据
第一次了解leveldb可能会疑惑L0-L6是怎么一回事。 其实这也是leveldb的创新之处,也是它名字的由来。之前不是说lsm-tree的查找需要找所有的文件吗?
你当然可以随机依次去搜索数据,但是别忘了数据的查找往往是存在局部性的,热点数据往往有更多机会被访问。
据此,leveldb设计出七个level层次的文件。它的思路如下:
- leveldb磁盘文件存储分为7个level(L0-L6),level越高,数量级别也越大,存储量也越大(是数量级的差别)
- 刚写入持久化的数据往往是在L0层次的,当文件达到一定大小会打开一个新的文件写入
- 当文件数量或达到阈值时,它会进行压缩,将该level中的几个文件压缩成下个level所规定的大小的,然后进入下个level
这样的效果就是最近修改的数据往往最先被访问(因为level小),但该部分数据往往占比不大,更老的数据就会访问优先级会比较低。 这样的好处就是符合时间局部性原则,理论上数据的访问会更快。
2.3 压缩
当写入越来越多时,某个level的文件数量也会越来越多。 而我们知道文件系统的文件描述符是有限的,而且过多的文件会造成查找效率下降的问题。 不仅如此,我们之前提过leveldb的删除操作并非真正删除,而是先标记,所以势必会造成冗余存储的问题。
所以一个level中达到阈值时会触发压缩,会将该level的几个文件压缩到下一level。这里的压缩是将几个文件合并成一个或多个新文件。这个过程可以这么理解,就是将几个小的有序树合并成一个大的有序树,在这个过程中会刨去那些已经标记删除的数据。
3.文件组成
对于研究数据存储,研究其持久化的文件组成是很有必要的。
Log files
每个更新都会写入该文件,当文件大小到达阈值(默认4KB),它会转化为一个sorted table,同时会创建一个新的log来应对接下来的更新。
sorted tables
- 真正存储数据的文件
- level越高,数量级别也越大,存储量也越大
Manifest
内容:
- 每个level的sorted table的文件名称
- 键值范围
- 一些其他的元数据
每当数据库被重新打开时,该文件就会被创建
current
一个记录了最近MANIFEST 文件名的文本文件
info logs
信息讲打印到一个名为LOG和LOG.old的文件中
其他
其他用于其他目的的文件也可能存在(LOCK,*.dbtmp)
4.数据恢复
这里考虑的就是宕机后根据之前写的log文件依次去重做数据操作的过程,步骤如下:
- 读取CURRENT以查找最近提交的MANIFEST的名称
- 读取命名的MANIFEST文件
- 清理陈旧文件
- 将日志块转换为新的0级sstable
- 开始将新写入定向到具有恢复序列的新日志文件
总结
leveldb是个根据lsm-tree设计的存储引擎,可以极大的提升写操作的效率,适合写多读少的场景。


评论